Demo #1
Demo #1
Demo #2
Demo #3
Demo #4
Demo #5
Demo #6
Demo #7
Demo #8
A Video World Model generates future frames conditioned on past frames and user actions. Its central weakness is memory: with only a limited context window, the model quickly forgets what it has already generated, so scenes drift and become inconsistent over long durations. A promising remedy is to keep previously generated frames as a memory bank and feed the relevant ones back as context. The question is how to decide which frames are relevant. Prior context-retrieval methods rely on hand-crafted rules — e.g., matching camera field-of-view overlap or point clouds — which break down in realistic scenes with occlusions and moving objects, where geometry alone cannot tell what actually matters.
Our key idea is a paradigm shift: instead of hand-crafted retrieval rules, we let the model learn to adaptively query its own memory end-to-end. Concretely, we introduce query tokens (Q) as an information bridge between context tokens (C) and predicted tokens (P): the Q tokens attend to C to gather the context that is actually useful, and the P tokens attend to Q as the condition for generation. Rather than adding a separate retrieval module — which we find fails to train from scratch (Figure 1) — we reuse the video generation model itself by feeding C, Q, and P tokens together, so context querying directly inherits the model's pre-trained visual priors. To keep this affordable on long videos, we further introduce two efficiency strategies for training and inference (Figure 2).
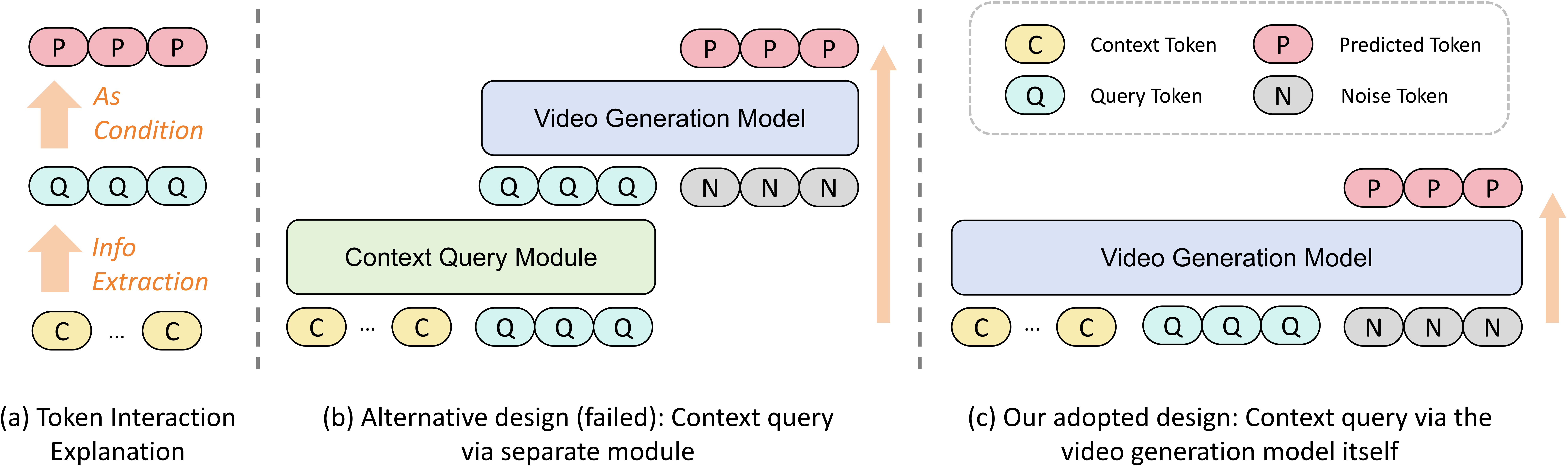
Figure 1. Architecture clarification. (a) Interaction mechanism among the context (C), query (Q), and predicted (P) tokens. (b) & (c) Two designs for context querying: the alternative design in (b) fails in our experiments, while the adopted design in (c) leverages the prior knowledge of the video generation model itself and performs effectively.
Figure 2. Efficiency Strategies. (a) Strategy #1: context querying is performed in the shallow Query Layers with C, Q, P tokens, while the deep Generative Layers process only Q, P tokens. (b) Strategy #2: unnecessary attention computation is removed for improved efficiency.
@inproceedings{yu2026memlearner,
title = {MemLearner: Learning to Query Context Memory for Video World Models},
author = {Yu, Jiwen and Gao, Jianxiong and Bai, Jianhong and Qin, Yiran and
Huang, Kaiyi and Liu, Quande and Wang, Xintao and Wan, Pengfei and
Gai, Kun and Liu, Xihui},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2026}
}